2.9.2 Restructuring from paneldata to cross-sectional data
Datasets created through one of the commands import-panel or
reshape-to-panel are of the panel / long format type where repetitive variable observations are organized vertically at record level. The reshape-from-panel command makes it possible to change the data structure to wide-format where the information is structured horizontally at the variable level with one record per unit.
All variables in the panel dataset you are in are restructured to wide format after the command is run, and the variables are given a suffix based on the sublevel given by the auxiliary variable date@panel1. Note that also variables for fixed information will be duplicated with suffixes related to sublevel (although they do not change over time). This can be solved by deleting redundant variables after the dataset has been converted.
The illustration below shows how the restructuring logically takes place under the hood. The example shows a data set with long format that contains the variables sivstand (marital status), lønn (yearly wage) and kjønn (gender), in addition to the auxiliary variable date@panel which contains the value of the sublevel, in this case the years 2018-2020 (double digits). The dataset is converted to wide format using the reshape-from-panel command. Note that you do not specify variables or prefixes. All variables are converted to wide format with associated suffixes, including variables that measure fixed information such as gender.
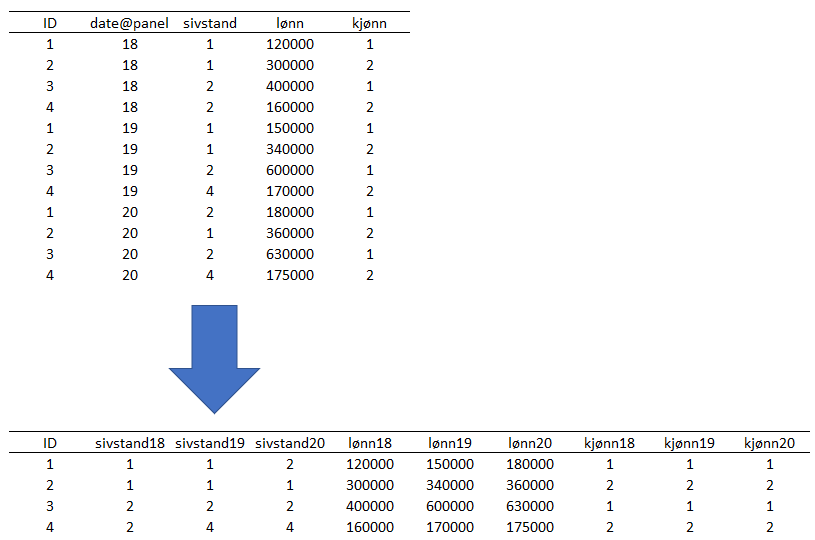
The reshape-from-panel command completes by allowing you to convert back and forth between wide- and long-format, providing the following
possibilities:
-
It is not possible to import new variables into a dataset created using the
import-panelcommand. This can be solved by usingreshape-from-panelto convert to wide-format, and then import new variables as needed usingimport. Once you have the variables you need, you can convert back to panel / long format again by using thereshape-to-panelcommand. -
Panel datasets provide less flexibility when comparing and performing operations over variable values across sub-levels (over time). Examples of this are when you want to create a variable that consists of the average wage measured over 2019 and 2020, or when you want to create a condition that is based on cases where the yearly wage in 2020 is greater than in 2019. This can also be solved by converting to wide-format, then do the desired operations and convert back afterwards.
Example: Restructure datasets from long to wide format
Footnotes
-
For classical panel dataset created by using the
import-panelcommand, the suffixes are somewhat different. When usingtabulate-panelorsummarize-panelon such datasets, it will appear that the sublevel has values of the type “YYYY-MM-DD”, but this only applies as a display format. In this case, the actual values for date@panel use reference dates as the value format (number of days measured from 1/1 1970). This is solved by renaming the variable names with therenamecommand in the final step. ↩